영화 추천 시스템 강의
이 강의에서는 상관계수 기반 추천 시스템과 코사인 유사도 기반 추천 시스템을 단계별로 구현하는 방법을 학습한다. 실습을 통해 데이터를 로드하고 전처리한 후, 추천 알고리즘을 적용하는 과정을 수행할 것이다.
1. 환경 설정 및 데이터 로드
1.1 데이터 파일 업로드
구글 코랩을 사용하여 movie_title.csv와 movie_review.csv 파일을 업로드한다.
from google.colab import files
# 사용자가 파일을 업로드할 수 있도록 요청
uploaded = files.upload()1.2 데이터 읽기
데이터를 pandas를 사용하여 읽어온다.
import pandas as pd
# CSV 파일을 데이터프레임으로 읽어오기
movies = pd.read_csv("movie_title.csv")
reviews = pd.read_csv("movie_review.csv")
1.3 데이터 확인
데이터가 올바르게 로드되었는지 확인한다.
# 첫 5개의 데이터를 출력하여 데이터 확인
print(movies.head())
print(reviews.head())
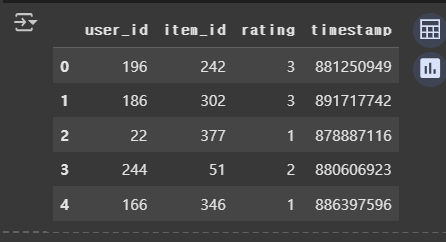
출력 예시:
movie_id title
0 1 Toy Story
1 2 Jumanji
user_id movie_id rating timestamp
0 196 242 3.0 978302109
2. 데이터 병합 및 전처리
2.1 영화 제목과 평점 데이터를 병합
reviews 데이터와 movies 데이터를 movie_id를 기준으로 병합한다.
# movie_id를 기준으로 데이터 병합
merged_df = pd.merge(reviews, movies, on="movie_id")
print(merged_df.head())
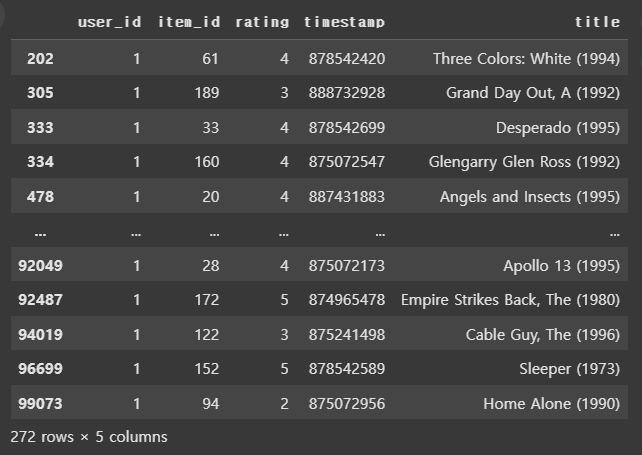
2.2 특정 사용자가 본 영화 찾기
예를 들어, user_id = 1인 사용자가 본 영화 목록과 별점을 조회한다.
user_id = 1
# 특정 사용자의 영화 목록과 별점 필터링
user_movies = merged_df[merged_df['user_id'] == user_id]
print(user_movies[['title', 'rating']])

2.3 별점 분포 시각화
사용자들이 부여한 영화 별점의 분포를 히스토그램으로 시각화한다.
import matplotlib.pyplot as plt
import seaborn as sns
# 히스토그램을 이용해 영화 별점의 분포를 시각화
plt.figure(figsize=(10, 5))
sns.histplot(merged_df['rating'], bins=10, kde=True)
plt.title("영화 별점 분포")
plt.xlabel("별점")
plt.ylabel("빈도")
plt.show()



3. 상관계수 기반 추천 시스템
3.1 유저-영화 평점 행렬 생성
각 사용자의 영화 별점을 행렬 형태로 변환한다.
# 유저 ID를 행(index), 영화 제목을 열(columns)로 하는 피벗 테이블 생성
ratings_matrix = merged_df.pivot_table(index='user_id', columns='title', values='rating')

3.2 상관계수 계산
피어슨 상관계수(Pearson Correlation Coefficient)를 사용하여 영화 간 유사도를 계산한다.
# 피어슨 상관계수를 이용해 영화 간 유사도 행렬 생성
corr_matrix = ratings_matrix.corr(method='pearson')

3.3 특정 영화와 유사한 영화 찾기
예를 들어, "Toy Story"와 가장 유사한 영화를 찾는다.
movie_name = "Toy Story"
# 특정 영화의 상관관계를 정렬하여 유사한 영화 찾기
similar_movies = corr_matrix[movie_name].dropna().sort_values(ascending=False)
print(similar_movies.head(10))

3.4 오류 발생 원인 및 해결
오류 예시:
KeyError: 'Toy Story'
해결 방법:
- ratings_matrix의 컬럼 이름에 불필요한 공백이 포함될 수 있으므로, strip()을 사용하여 공백을 제거한다.
ratings_matrix.columns = ratings_matrix.columns.str.strip()
4. 코사인 유사도 기반 추천 시스템
4.1 코사인 유사도 계산
코사인 유사도를 사용하여 유저 간의 유사도를 측정한다.
df_similar_movie = pd.DataFrame()
for i in range(24) :
print(my_rating['title'][i],my_rating['rating'][i])
movie_title=my_rating['title'][i]
recom_movie = df_corr[movie_title].dropna().sort_values(ascending=False).to_frame()
recom_movie.columns = ['correlation']
recom_movie['weigth'] = recom_movie['correlation']*my_rating['rating'][i]
df_similar_movie = pd.concat([df_similar_movie,recom_movie])4.2 특정 유저와 유사한 유저 찾기
특정 사용자(예: user_id=1)와 가장 유사한 사용자를 찾는다.
# 특정 사용자의 유사도 점수를 정렬
my_rating=df.loc[df['user_id']==4,['user_id','title','rating']].reset_index(drop=True)5. 추천 결과 분석 및 시각화
5.1 추천 영화 시각화
유사한 영화 추천 결과를 막대 그래프로 시각화한다.
# 추천된 영화 목록 가져오기
top_movies = similar_movies.head(10).index.tolist()
top_ratings = similar_movies.head(10).values
plt.figure(figsize=(12, 6))
sns.barplot(x=top_movies, y=top_ratings)
plt.xticks(rotation=45)
plt.xlabel("영화")
plt.ylabel("유사도")
plt.title("유사한 영화 추천")
plt.show()
6. 실습 문제 및 정답 코드
문제 1: 특정 사용자가 본 영화 목록을 조회하는 코드를 작성하세요.
문제 2: 특정 영화와 가장 유사한 5개의 영화를 찾는 코드를 작성하세요.
문제 3: 상관계수와 코사인 유사도를 비교하고 차이를 설명하세요.
정답 코드:
# 특정 사용자의 영화 목록 조회
user_id = 10
print(merged_df[merged_df['user_id'] == user_id][['title', 'rating']])
# 특정 영화와 유사한 5개의 영화 찾기
movie_name = "Jumanji"
print(corr_matrix[movie_name].dropna().sort_values(ascending=False).head(5))
상관계수 기반 추천은 영화의 평점 상관관계를 사용하고, 코사인 유사도는 벡터 유사도를 이용한다.
상관계수는 연관성이 높은 영화들을 추천하지만, 코사인 유사도는 사용자의 패턴을 보다 정밀하게 반영한다.
'🐍 Python' 카테고리의 다른 글
| Hugging Face 파이프라인 사용법 총정리: 감정 분석부터 번역, 이미지 분류까지 한 번에!" (0) | 2025.02.10 |
|---|---|
| Hugging Face로 시작하는 Transformer 모델 완벽 활용 가이드: GPT부터 BERT, T5까지 (0) | 2025.02.10 |
| VS Code 과 Jupyter Notebook / Python 코드 실행 방법, 비교 & 활용 가이드 (0) | 2025.02.09 |
| 범주형 데이터를 숫자로 변환하는 방법: One-Hot Encoding 완벽 가이드 (0) | 2025.02.09 |
| LabelEncoder란? 머신러닝에서 범주형 데이터를 숫자로 변환하는 방법 (0) | 2025.02.09 |