728x90
[수업 정리: 모델 평가 및 업로드 과정]
1. 데이터 출처 및 개요
본 실습에서는 Hugging Face의 사전 학습된 모델과 IMDB 감성 분석 데이터셋을 활용하여 파인튜닝을 진행합니다.
- 데이터 출처:
- IMDB 데이터셋: 영화 리뷰에 대한 감성 분석 데이터셋 (긍정/부정 라벨 포함)
- Hugging Face Hub에서 제공하는 사전 학습된 모델을 활용하여 파인튜닝 진행
- 실습 개요:
- 사전 학습된 모델을 불러와 추가 학습(Fine-tuning)
- 학습된 모델을 평가하고 최적의 하이퍼파라미터 탐색
- 학습된 모델을 Hugging Face Hub에 업로드하여 공유 및 배포
- 업로드된 모델을 활용하여 감성 분석 수행


2. 사전 준비 및 모델 불러오기
2.1. 필요한 라이브러리 임포트
from transformers import Trainer, TrainingArguments, AutoModelForSequenceClassification, AutoTokenizer
from datasets import load_dataset
import torch
2.2. 사전 학습된 모델 불러오기
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
- distilbert-base-uncased 모델을 활용하여 감성 분석을 수행합니다.
- num_labels=2로 설정하여 긍정(1)과 부정(0) 두 가지 감성을 분류합니다.
2.3. 데이터셋 로드 및 토크나이징
dataset = load_dataset("imdb")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
- IMDB 데이터셋을 불러와 텍스트를 토큰화합니다.

그래프 설명 (순차적 과정)
모델 학습 및 평가 과정은 Train → Test → Unsupervised(비지도 학습) 순서로 진행됩니다.
데이터 셋의 구조

DatasetDict 구조 표로 정리
| 데이터셋 유형 | 데이터 수 | 주요 특징 | 역할 |
| Train (학습 데이터셋) | 25,000개 | text (리뷰), label (감성 분석) | 모델 학습 (Supervised Learning) |
| Test (테스트 데이터셋) | 25,000개 | text (리뷰), label (감성 분석) | 모델 성능 평가 |
| Unsupervised (비지도 학습 데이터셋) | 50,000개 | text (리뷰) / label이 없을 수도 있음 | 추가적인 데이터 활용 (비지도 학습) |
토큰화 과정 한눈에 정리
왜 토큰화가 필요할까?
- 모델은 텍스트가 아닌 숫자 형태의 데이터를 이해함
- 문장을 그대로 입력할 수 없으므로 단어를 숫자로 변환해야 함
- 문장의 길이가 제각각이므로 최대 길이를 맞추고, 필요하면 자르거나 채워야 함
- 예측할 때도 토큰화를 했듯이, 학습할 때도 동일한 방식으로 진행해야 함
토큰화를 하면 무엇이 나올까?
- 숫자로 변환된 문장 (단어를 숫자로 매핑)
- 어텐션 마스크 (패딩된 부분을 무시하도록 설정)
어떻게 적용할까?
- 모든 데이터를 일일이 변환하면 시간이 오래 걸리므로, 자동화된 함수를 만들어 적용
- 한 번 만든 함수를 학습 데이터뿐만 아니라, 모델이 사용할 모든 데이터에 동일하게 적용


Hugging Face API 인증 및 모델 업로드 과정
Hugging Face Hub에 모델을 업로드하려면 API 인증 과정이 필요합니다.
- 구글 아이디로 로그인 & API 키 생성
- Hugging Face 웹사이트에서 구글 계정으로 로그인합니다.
- 계정 설정에서 Access Token (API 키) 을 생성합니다.
- 이 키는 모델 업로드 및 인증 과정에서 필요합니다.
3. 모델 학습 및 평가 (Fine-Tuning & Evaluation)
3.1. 학습 설정 및 모델 훈련
# 아래 두 항목을 사용하기 위해서 라이브러리 임포트를 해야 한다.
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results", # 학습 결과를 저장할 디렉토리
evaluation_strategy="epoch", # 매 에포크마다 평가를 수행
per_device_train_batch_size=8, # 학습 시 사용할 배치 크기 (디바이스당 8개 샘플)
per_device_eval_batch_size=8, # 평가 시 사용할 배치 크기 (디바이스당 8개 샘플)
num_train_epochs=3, # 전체 학습을 3번 반복 (에포크 수)
save_steps=1000, # 1000 스텝마다 모델을 저장
save_total_limit=2 # 최대 2개의 체크포인트만 저장 (이전 체크포인트 자동 삭제)
)
# Trainer 설정
trainer = Trainer(
model=model, # 훈련할 모델 지정
args=training_args, # 학습 관련 설정 (TrainingArguments에서 정의한 값 사용)
train_dataset=tokenized_datasets['train'], # 학습 데이터셋
eval_dataset=tokenized_datasets['test'], # 평가(테스트) 데이터셋
tokenizer=tokenizer # 토크나이저 (입력 데이터를 모델이 이해할 수 있도록 변환)
)
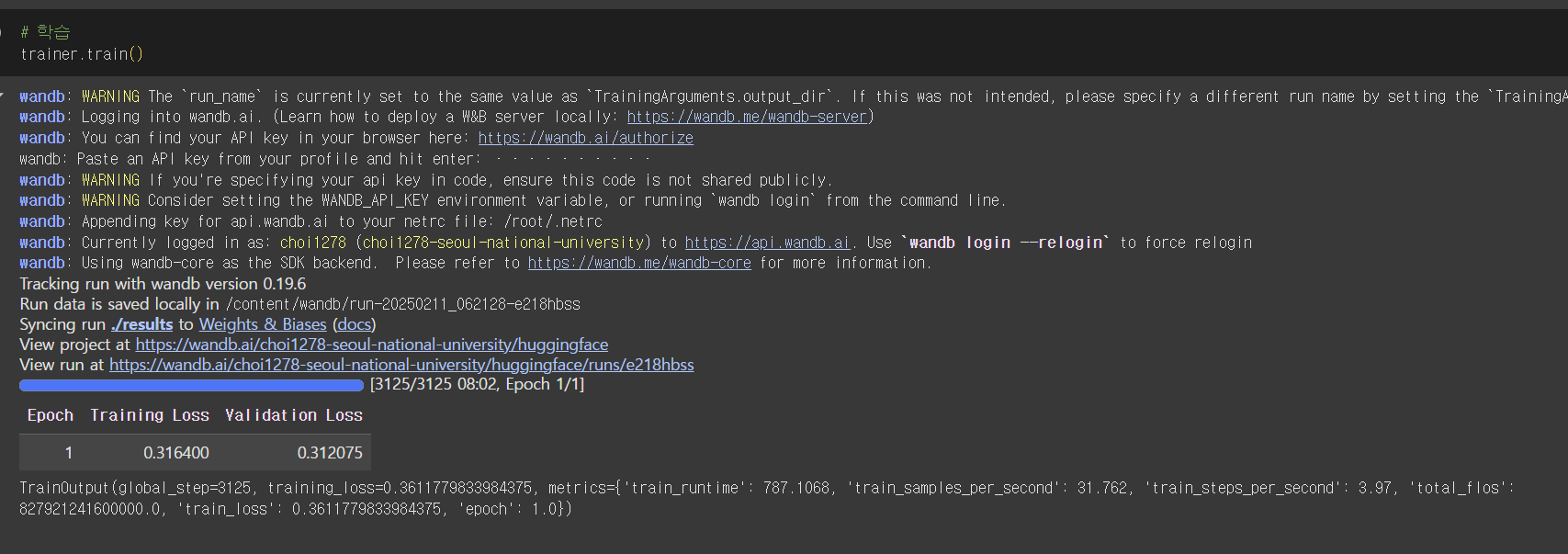
trainer.train()- num_train_epochs=3 설정으로 3번의 에포크 동안 모델을 학습합니다.
- evaluation_strategy="epoch"로 설정하여 매 에포크마다 평가를 수행합니다.
3.2. 테스트 데이터 평가 실행
trainer.evaluate()
- 학습된 모델을 테스트셋을 통해 평가하는 과정입니다.
- 학습 데이터는 25,000개이며, 평가 데이터도 동일한 개수입니다.
3.3. 평가 결과 해석
loss = trainer.evaluate()["eval_loss"]
print(f"손실 값: {loss:.3f}")
- 평가 결과에서 손실 값(Loss) 을 확인합니다.
- 손실 값이 작을수록 성능이 좋음을 의미합니다.
- 일반적으로 0.4 이하라면 준수한 성능을 보입니다.
4. 모델 업로드 및 배포
4.1. 모델 저장하기
trainer.save_model("./results")
4.2. Hugging Face 모델 저장소에 업로드하기
from huggingface_hub import upload_folder, login
login(token="your_token_here")
upload_folder(
folder_path="./results",
repo_id="사용자명/모델명",
repo_type="model"
)


- repo_id에는 본인의 Hugging Face 계정과 모델명을 입력해야 합니다.
- 정상적으로 업로드가 완료되면 Hugging Face 웹사이트에서 모델을 확인할 수 있습니다.


5. 모델 배포 후 활용하기
5.1. 저장된 모델을 다운로드하여 활용
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("사용자명/모델명")
tokenizer = AutoTokenizer.from_pretrained("사용자명/모델명")
5.2. 파이프라인을 활용한 예측
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
result = classifier("I love this movie! It was fantastic!")
print(result)
6. 결론
- 사전 학습된 모델을 활용한 파인튜닝 과정과 배포 방법을 학습했습니다.
- Hugging Face 모델 허브를 이용하여 모델을 저장 및 공유할 수 있습니다.
- Fine-tuned 모델을 배포하여 API로 활용할 수 있습니다.
위 과정을 이해하고 따라 하면, 본인의 모델을 다양한 환경에서 배포하고 활용할 수 있습니다. 🚀
728x90
'🐍 Python' 카테고리의 다른 글
| LLM + RAG 활용 AI 시스템 정리 (0) | 2025.02.12 |
|---|---|
| BERT 활용한 NLP 모델 예측 및 토큰화 완벽 가이드 (코드 포함) (0) | 2025.02.11 |
| 허깅 페이스(Hugging Face)로 오브젝트 디텍션: 소화전 탐지 모델 만들기 A to Z (0) | 2025.02.11 |
| Hugging Face 파이프라인 사용법 총정리: 감정 분석부터 번역, 이미지 분류까지 한 번에!" (0) | 2025.02.10 |
| Hugging Face로 시작하는 Transformer 모델 완벽 활용 가이드: GPT부터 BERT, T5까지 (0) | 2025.02.10 |